Spark处理并行问题的逻辑比较简单,将一个大的数据集拆分成若干小的数据集,将各个小的数据集,然后对这些小的数据集用相同的程序来处理,得到结果之后再重新聚集到一起。Spark是在MapReudce编程模型下,加入了“内存计算”和“DAG”拥有较高运算效率的。这篇文章,对Spark整个运行流程进行一个介绍。
基本概念与架构
硬件资源的发展。由于内存资源的扩大,可以进行内存计算。所以,这里提出了RDD的概念。
然后建立directed acyclicity graph/DGA,进一步提高执行效率。不需要Map和Reduce之间的等待。
在RDD和DGA的基础上,以进程+线程的方式提高响应速度。Task是最小执行单位。stage是可并行执行的task的集合。stage的集合是job。
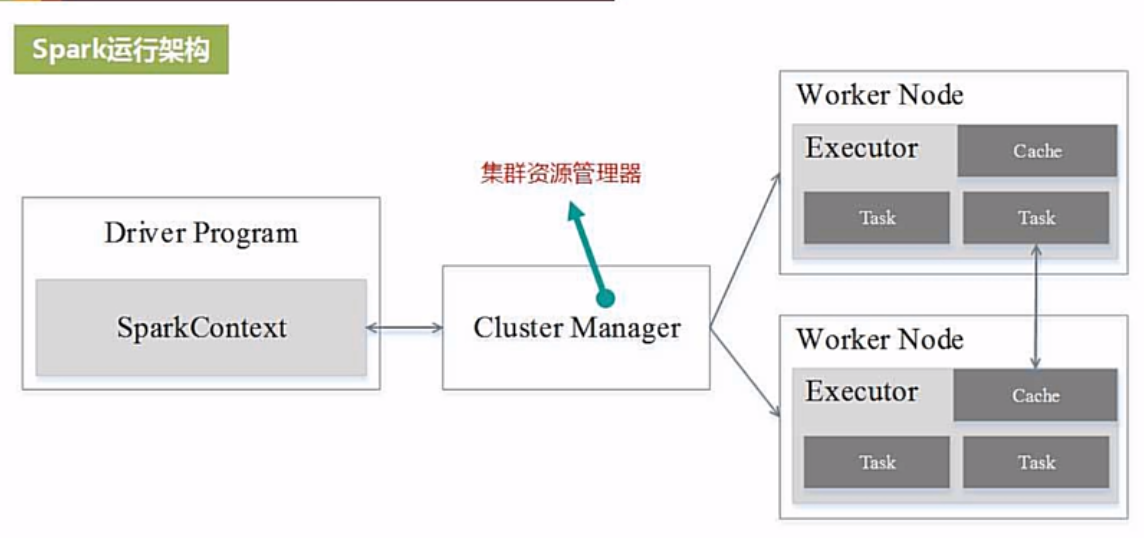
硬件资源是通过cluster manager(cm)与deriver program交互的。dp在各个work node上若干启动进程,进程再启动线程,线程去运行任务。
注意:
(1)线程的响应速度快;
(2)executor中有blockmanager,就是有限进行基于内存的计算,溢出是在硬盘执行。
(3)job1与job2之间没有联系。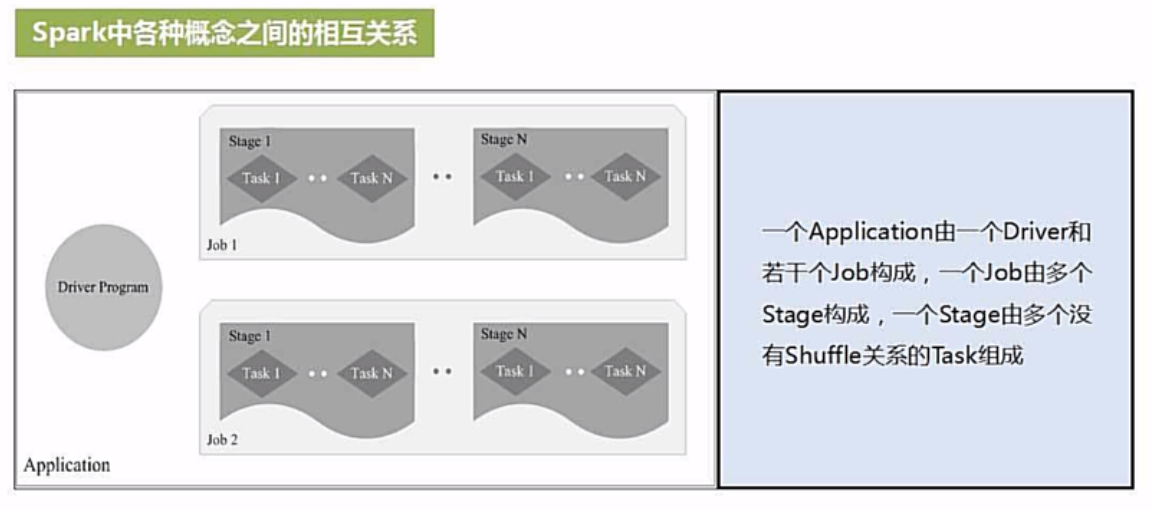
基本运行流程(Execution of Spark at cluster)
deriver program(dp)
dp用来构建Application(app)与集群的连接,通过spark context(sc)这个对象。
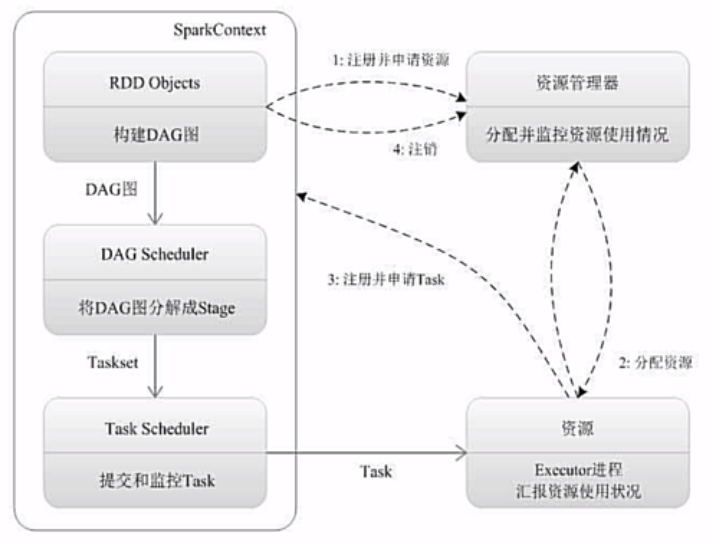
假设app在node1上提交,就要在node1上创建一个driver programm,dp相当于管家程序。由driver programm去创建一个sc,这个sc相当于一个桥梁,将dp与硬件资源(cluster resource/cr)联系起来。sc本身是一个对象,里面又一些方法,编程时需要“new”一个sc。通过sc中的各种方法,我们可以去访问资源。
sc创建完成后,就会向rc申请资源,但是不是直接向rc申请资源,而是向cm申请。也就是说cm掌握着cr。cr包括CPU与memory。
sc的另外一个作用是计算任务(task)的分配与监控。
cluster management(cm)
在dp创建sc的同时,cm也需要把resource管理好。dp向cr申请资源,本质上从通过spark context向cluster management申请,也就是说cm在管理cluster,分发cpu与内存等资源。
cm会在cluster的work node上启动进程,这个进程称为executor,然后executor再去启动线程(thread),再有threads去执行tasks,一个thread对应一个task。
注:executor中的线程是也是由cluster manager分配的。
spark context(sc)
sc一方面想cm申请资源,另一方面分配任务。其分配任务的机制是根据RDD依赖关系生成有向无环图(DAG),DGA会被提交到DGA scheduler将DGA分解成多个stage。一个stage相当于一个task_set,所以stage会被进一步扔给底层的task scheduler(ts),ts决定task分发往某个work node。
work node需要主动向sc申请运行任务,ts按照计算向数据靠拢的原则,把任务优先发送给数据所在work node。分配完任务后,executor启动线程执行task,结束后,反馈给ts。
该运行流程的特点
- 每个Application有一个专属的executor,在APP运行期间一直驻留,这就没有切换开销。executor以多线程方式运行task,所以响应时间短,启动开销小。
- 计算过程与rm无关。
- Task的分配基于两个原则:(1)数据本地性;(2)推测执行机制;