Spark是一种分布式处理技术,运行在CPU集群上。作为高性能计算的软件框架之一,Spark具有诸多优点,特别擅长于大数据处理。相较于Hadoop,Spark发明了(1)内存计算技术;(2)DAG。这两项技术提高了Map-Reduce编程模型的计算效率,适用于迭代运算。目前,spark已经成为了大数据处理的主流软件。
本节概述
Spark来源于伯克利大学的实验室。主要创新点是内存计算和DAG。
这篇文章的主要目的是介绍如何独立的编写Spark应用程序。Spark的优点是我在单机上跑成功的应用程序,在集群上也能成功,这是MPI不具备的,这个特点大大提高了编程效率。所以,编写Spark应用程序的步骤就可以分解为:(1)在单机上编写测试一个Spark应用程序;(2)然后在拿到集群上去运行。
1. Spark 安装
spark 在集群上部署:deploy Spark on cluster/cloud
2. 使用Spark shell
spark shell是一种交互式界面,可以逐行交互式的运行语句。便于学习Spark API。
Spark shell启动之后实际上已经开启了一个deriver program,或者说本身就是一个driver program(任务控制节点)。任何一个Application必须有一个driver program,伴随Application运行的全过程,driver program开启在这个application提交的节点上,一般是管理节点。
driver program再通过spark context对象与集群的硬件资源连接。driver内部有main函数和分布式数据集。
启动spark shell时,单机模式可以配置线程的数量,集群模式有三种cluster manager。1
2./bin/spark-shell --master local[4]
./bin/spark-shell --master spark://HOST(主机名的名称):PORT(7077) 以spark standalone模式链接到指定集群的主节点。
进入spark shell之后就可以在shell中编写代码。
3. Spark独立应用程序编写与运行
假设存在一个用scala编写好的spark独立应用程序,要运行它首先要进行打包编译。这里就需要介绍scala的打包编译工具,sbt(java用maven进行打包编译,python不需要打包,直接通过spark-submit命令提交)。
3.1 安装sbt
3.2 编写应用程序
目录结构要符合规范。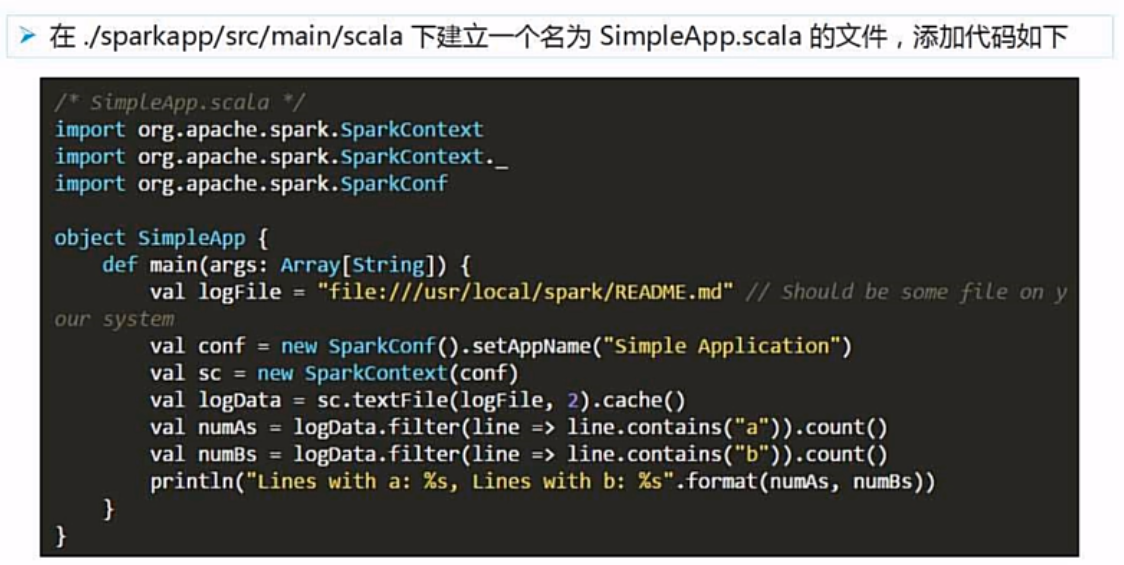
3.3 用sbt打包
新建simple.sbt文件,在该文件中添加必要信息。1
2
3
4name := "simpleProject(工程名称任意取)"
version := "1.0"(自己编写的用户程序的版本)
ScalaVersion := "2.11.8"(spark所依赖的scala的版本)
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"(依赖的库函数,要那些就加进去哪些,现在就只要spark的核心包)
为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:cd ~/sparkapp
find .
3.4进行具体的打包编译
/usr/local/sbt/sbt package
打包编译之后,会自动生成一个target目录,生成的jar包会保存在target目录下面。
3.5向spark提交jar包
spark-submit (里面又一系列参数进行配置)
4. Spark集群环境搭建及在集群上运行sparkApp
4.1 集群环境搭建
1 主从架构,如:一主2从
2 HDFS有一个name node,和data node;
3 Spark有master node,和worker node;
4 部署时master node和name node部署在一起,data node和worker node部署在一起,这样可以方便数据靠拢的原则。HDFS完成数据存储,Spark core完成数据计算。
4.2 在集群上运行sparkApp
先启动hdfs,yarn,再启动spark
选择cluster manager
准备好jar包及其地址
开始向集群提交。
知道URL(地址)
spark://master:7077
通过web界面查看运行情况