1. 云中部署服务器
如果对集群没有长期持续的使用需求,在云上部署服务器来运行程序是相当划算,也是相当方便的选择。
目前全世界前三大云服务提供商是AWS,微软,阿里。
本地部署选择的服务器提供商是“vultr”, vultr的性价比很高。
这里安装了三台云服务器,机房地点西雅图,操作系统Ubuntu,提供内网IP。内网是指局域网,外网是指英特网,内网IP一般192开头。
Ref 内网和外网之间的通信
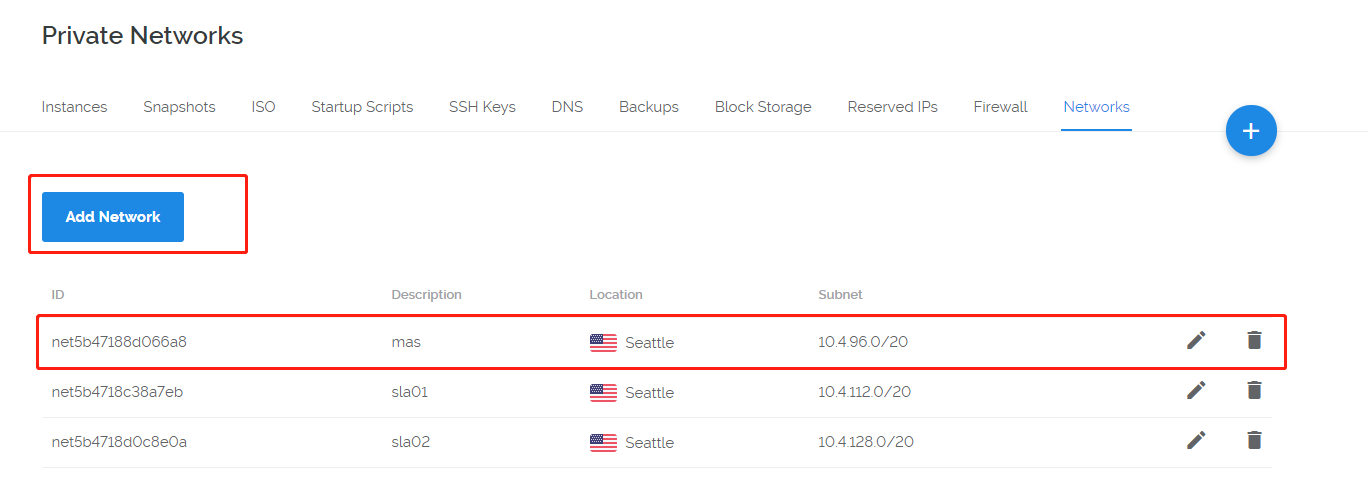
这里注意,在vultr上不直接提供内网的IP地址,需要自己配置。
内网一般以172,192开头。IP地址分类/IP地址10开头和172开头和192开头的区别
需要参考如下两篇文章:
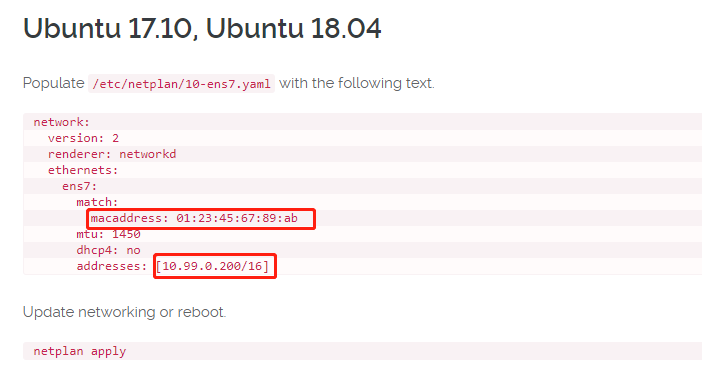
私有IP的配置比较tricky。这里简单列出几个关键步骤: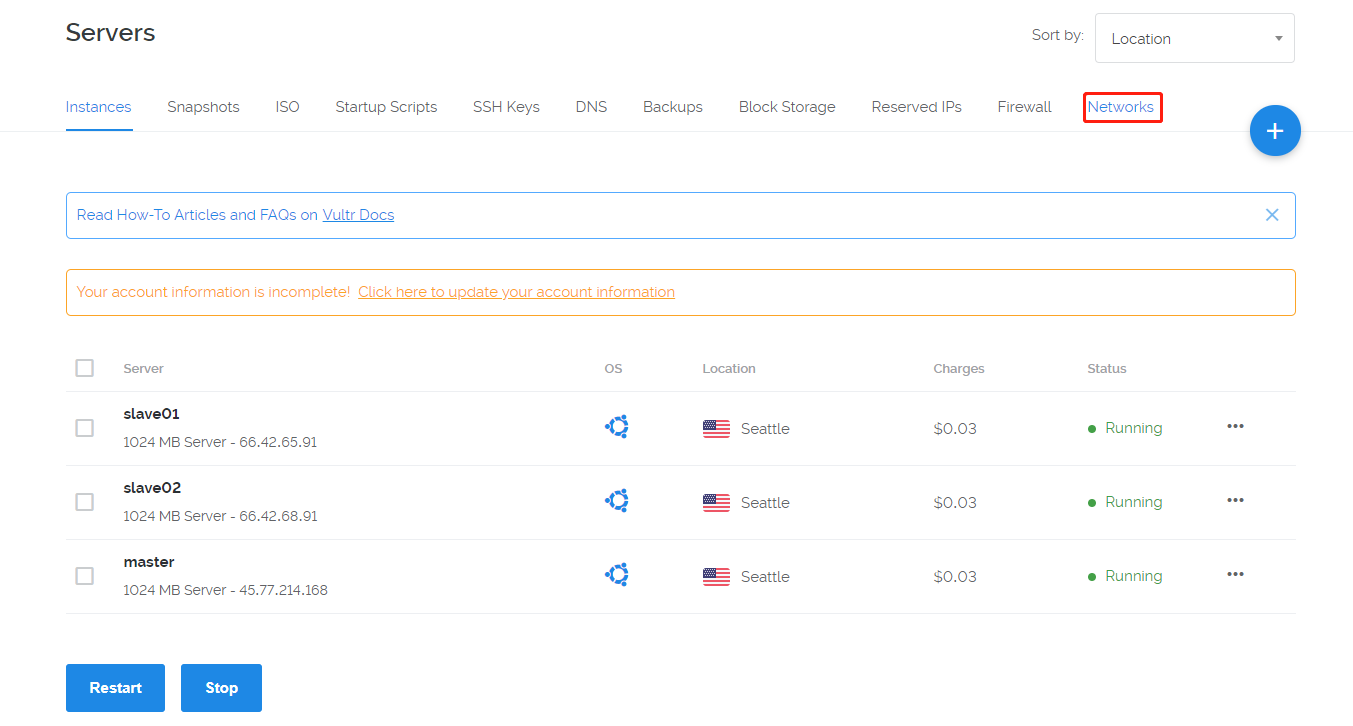
1
2
3vim /etc/netplan/10-ens7.yaml
netplan apply
ifconfig
配置完内网地址之后,ping一下这些地址,看看时候能互相ping通。
2. Hadoop 2.7.6分布式集群环境搭建
Ref Hadoop集群安装配置教程
2.1 集群配置
在网上租用几台服务器。vultr.
一个主节点,2个从节点。
三台电脑主机的用户名均为root.
2.1.1 相互ping通
三台机器可以ping双方的ip来测试三台电脑的连通性。1
2
3master: 10.25.96.3; root; #!m8W.8bZfXRyCraS
slave1: 10.25.96.4; root; #_vE2Q]M(E._#1?F-
slave2: 10.25.96.5; root; #-Ds7eWY-$!DNz4N,
查看当前主机打IP.注意,此处不是必须IP地址都在同一个局域网中。ifconfig
三台机器可以ping双方的ip来测试三台电脑的连通性。1
ping 66.42.65.91
2.1.2 change name
为了更好的在Shell中区分三台主机,修改其显示的主机名,执行如下命令1
sudo vim /etc/hostname
2.1.3 setting IP address
修改三台机器的/etc/hosts文件,添加同样的配置:1
2
3
4
5
6
7
8
9sudo vim /etc/hosts
127.0.0.1 localhost
10.25.96.5 slave02
10.25.96.4 slave01
10.25.96.3 master
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
2.1.4配置ssh无密码登录本机和访问集群机器
请运行如下命令,安装openssh-server,并生成ssh公钥。ssh-keygen -t rsa -P ""cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
1 | scp ~/.ssh/id_rsa.pub root@master:/root/ |
接着在slave01、slave02主机上将master的公钥加入各自的节点上,在slave01和slave02执行如下命令:cat ~/id_rsa.pub >> ~/.ssh/authorized_keysrm ~/id_rsa.pub
2.1.5 JDK
分别在master主机和slave01、slave02主机上安装JDK和Hadoop,并加入环境变量。
2.1.5.1 自动下载解压JDK
分别在master主机和slave01,slave02主机上执行安装JDK的操作1
sudo apt-get install default-jdk
2.1.5.2 JDK文件路径
编辑~/.bashrc文件,添加如下内容:export JAVA_HOME=/usr/lib/jvm/default-java
接着让环境变量生效,执行如下代码:source ~/.bashrc
2.2 Hadoop下载与路径配置
2.2.1 下载解压到指定文件夹
先在master主机上做安装Hadoop,暂时不需要在slave01,slave02主机上安装Hadoop.稍后会把master配置好的Hadoop发送给slave01,slave02.
在master主机执行如下操作:
首先要下载hadoop到本地1
2
3
4
5
6
7wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
cd /usr/local/
rm -rf hadoop/
rm -rf spark/
sudo tar -zxf ~/hadoop-2.7.6.tar.gz -C /usr/local
sudo mv ./hadoop-2.7.6/ ./hadoop
sudo chown -R root ./hadoop
2.2.2 Hadoop的文件路径配置
编辑vim ~/.bashrc文件,添加如下内容:1
2export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
接着让环境变量生效,执行如下代码:source ~/.bashrc
2.3 Hadoop参数配置
2.3.1 填写slave节点
修改master主机修改Hadoop如下配置文件,这些配置文件都位于cd /usr/local/hadoop/etc/hadoop目录下。
修改vim slaves:
这里把DataNode的主机名写入该文件,每行一个。这里让master节点主机仅作为NameNode使用。1
2slave01
slave02
2.3.2 填写core-site.xml
修改vim core-site.xml1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
2.3.3 填写hdfs-site.xml
修改vim hdfs-site.xml:1
2
3
4
5
6<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
2.3.4 填写mapred-site.xml
修改vim mapred-site.xml(复制cp mapred-site.xml.template mapred-site.xml,再修改文件名)1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.3.5 填写yarn-site.xml
修改vim yarn-site.xml1
2
3
4
5
6
7
8
9
10
11<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
2.4 压缩并发送与接收
2.4.1 压缩并发送到各个节点
配置好后,将 master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 master 节点主机上执行:1
2
3
4
5
6
7cd /usr/local/
rm -rf ./hadoop/tmp # 删除临时文件
rm -rf ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop
cd ~
scp ./hadoop.master.tar.gz slave01:/root
scp ./hadoop.master.tar.gz slave02:/root
2.4.2 在各个节点上解压
在slave01,slave02节点上执行:1
2
3sudo rm -rf /usr/local/hadoop/
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R root /usr/local/hadoop
2.5 启动hadoop集群
2.5.1 启动hadoop集群
在master主机上执行如下命令:1
2
3cd /usr/local/hadoop
bin/hdfs namenode -format
sbin/start-all.sh
2.5.2 检查是否成功
运行后,在master,slave01,slave02运行jps命令,查看:1
2
3
4
5
6
7
8
9
10
11
12
13
14jps
Master对开启如下进程
2512 ResourceManager
2759 Jps
2087 NameNode
2350 SecondaryNameNode
slave会开启如下进程
1865 NodeManager
1998 Jps
1679 DataNode
----------
/usr/local/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/input
/usr/local/hadoop/bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
/usr/local/hadoop/bin/hdfs dfs -ls /user/hadoop/input
2.5.3 关闭
关闭hadoop集群1
/usr/local/hadoop/sbin/stop-all.sh
注:主节点上压缩的Hadoop压缩包是配置好的,解压后就能使用。
3. 异常情况
Ref 解决联邦报错: IllegalArgumentException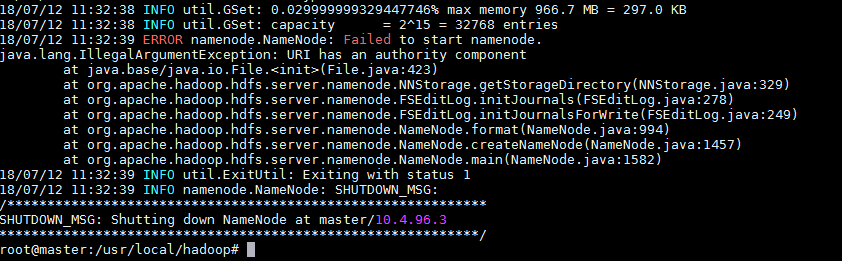
4. node stroage (Mirror)
Ref: